Alessandro Plantera
Tears
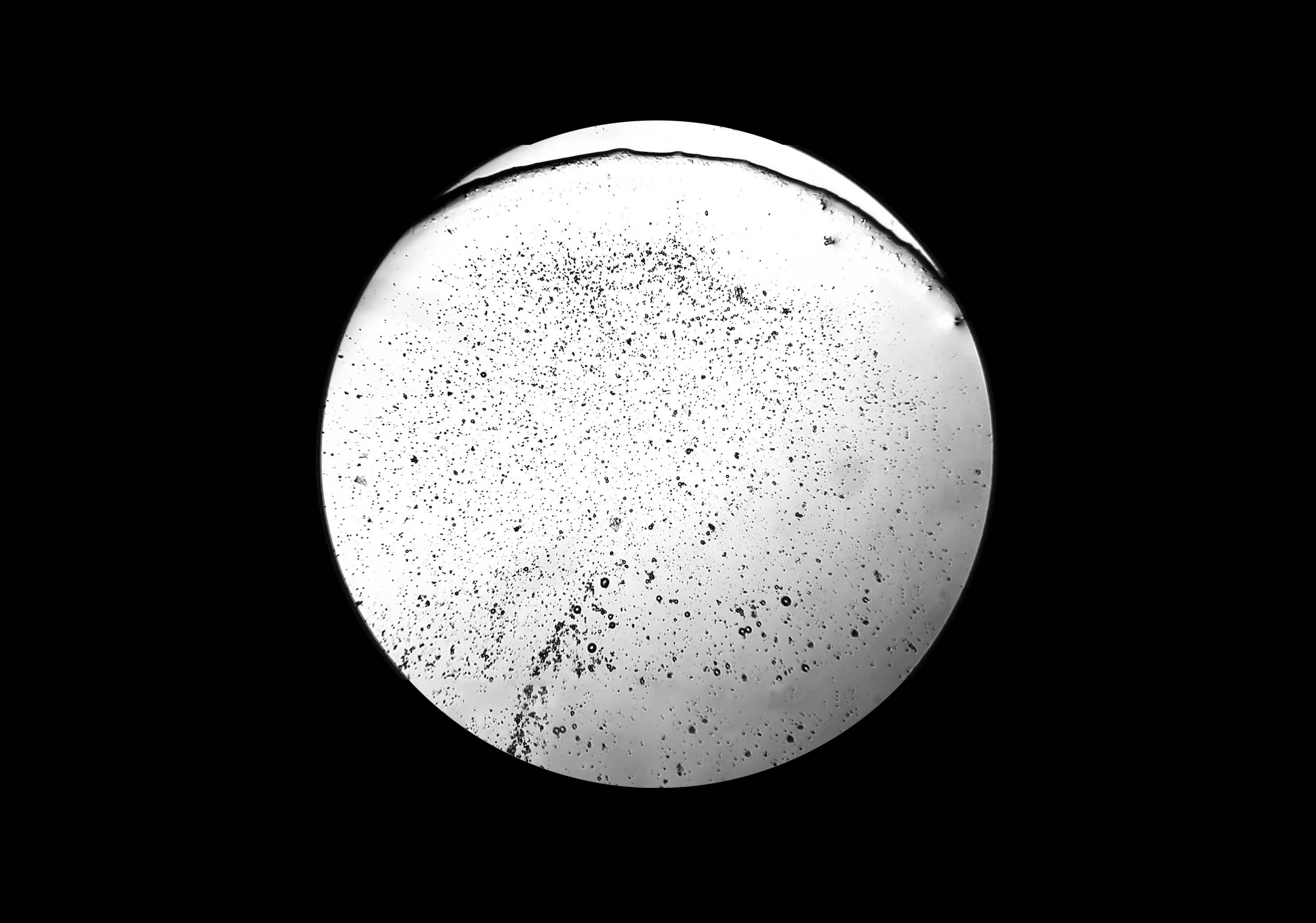
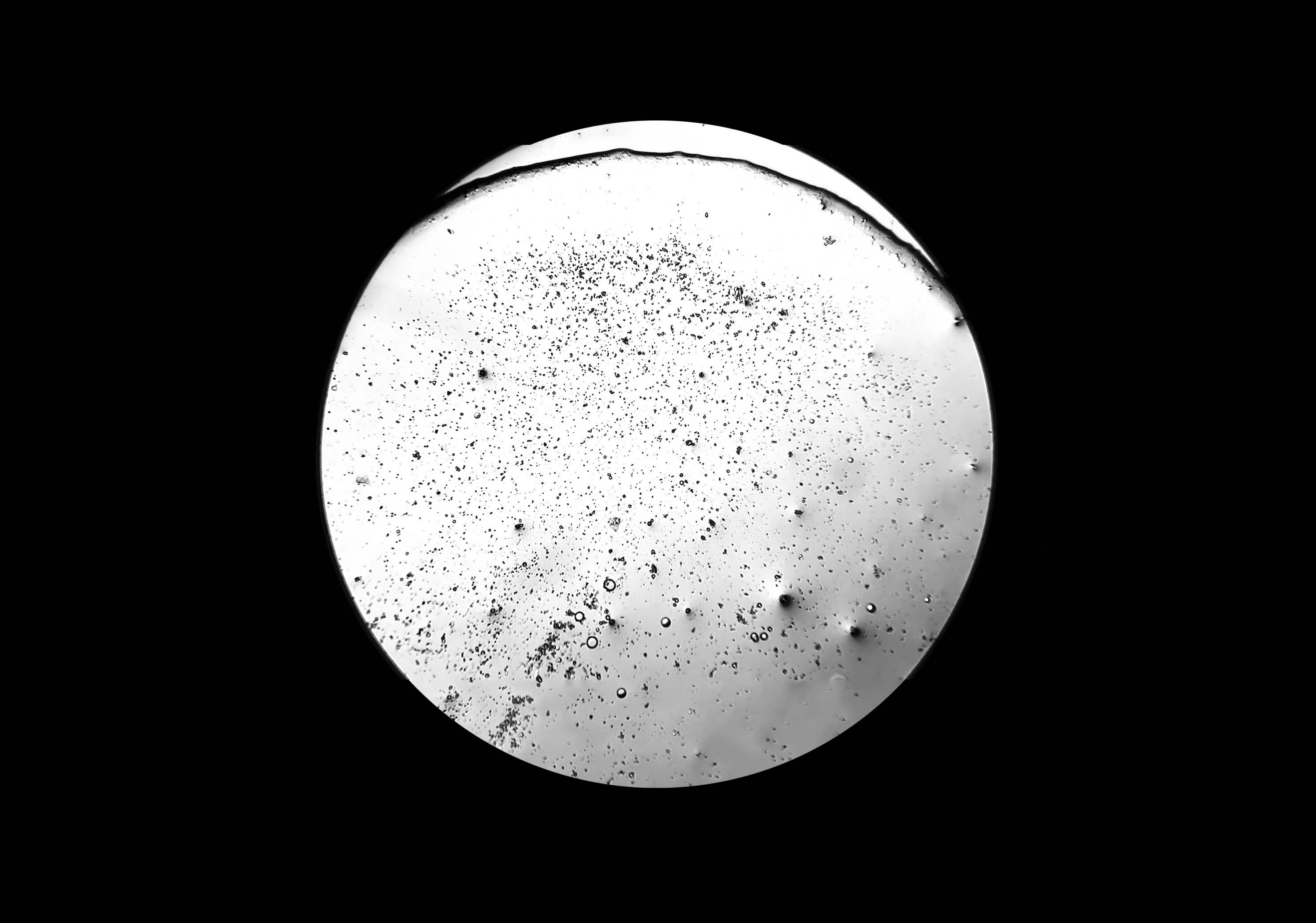
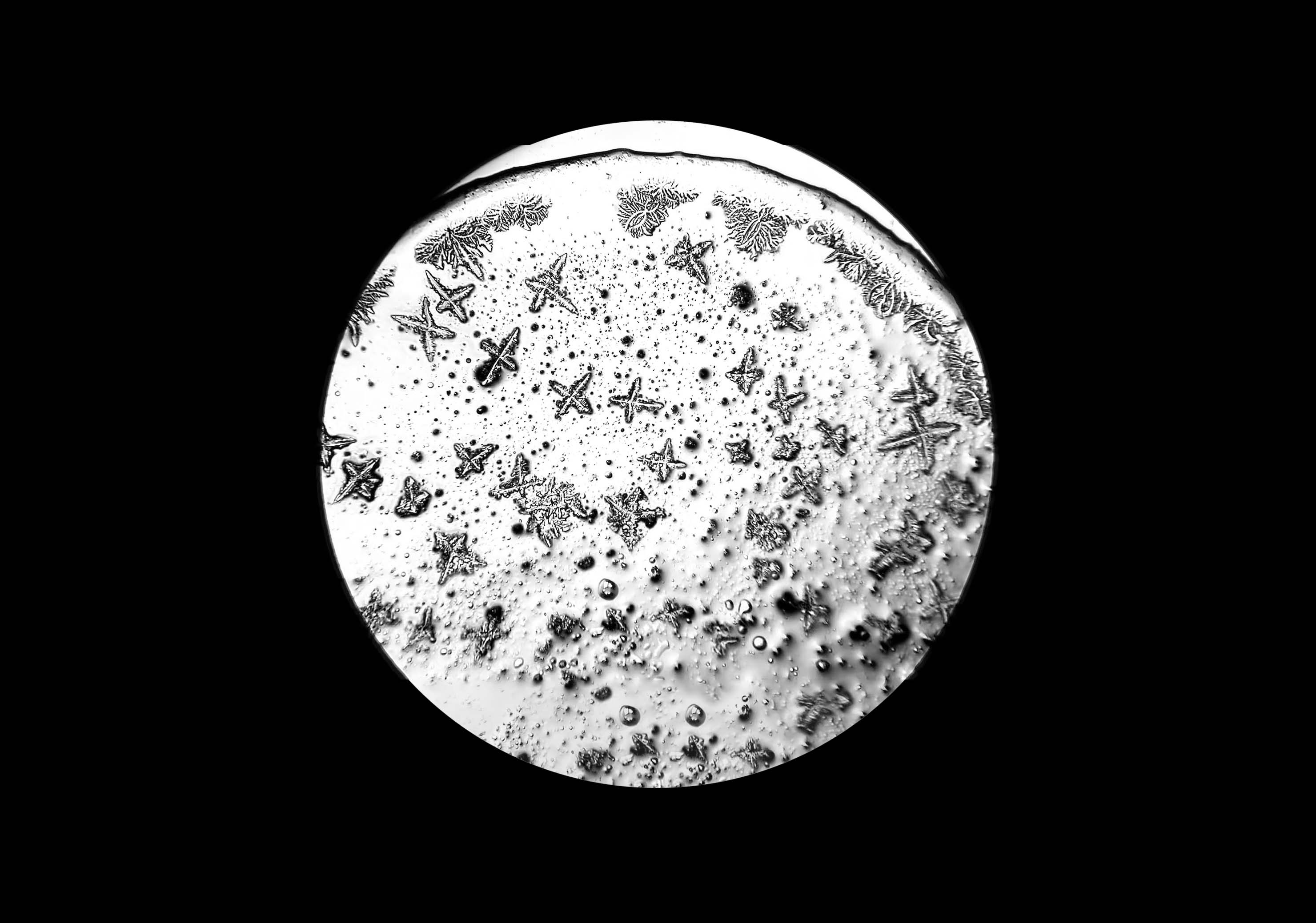
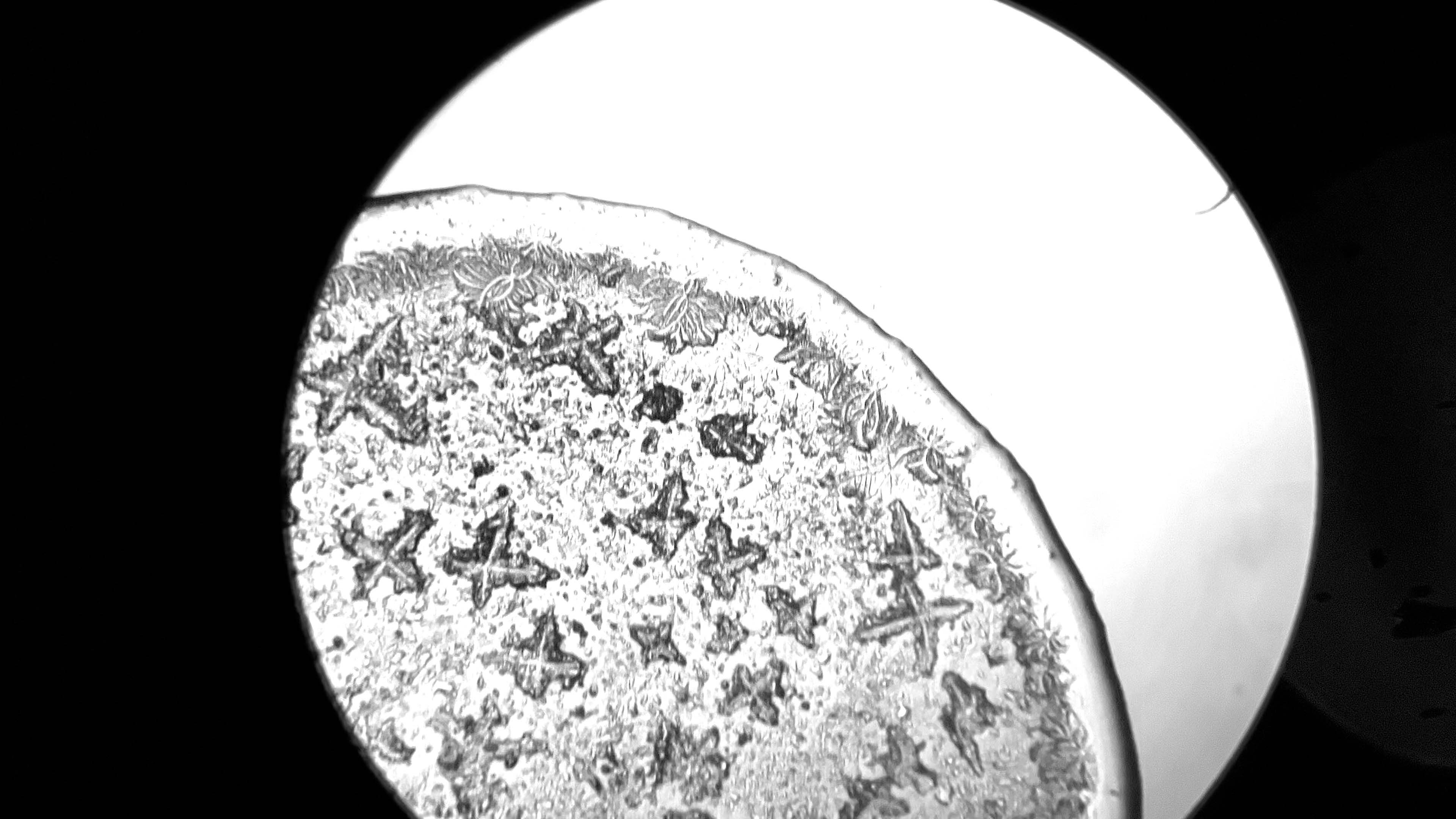
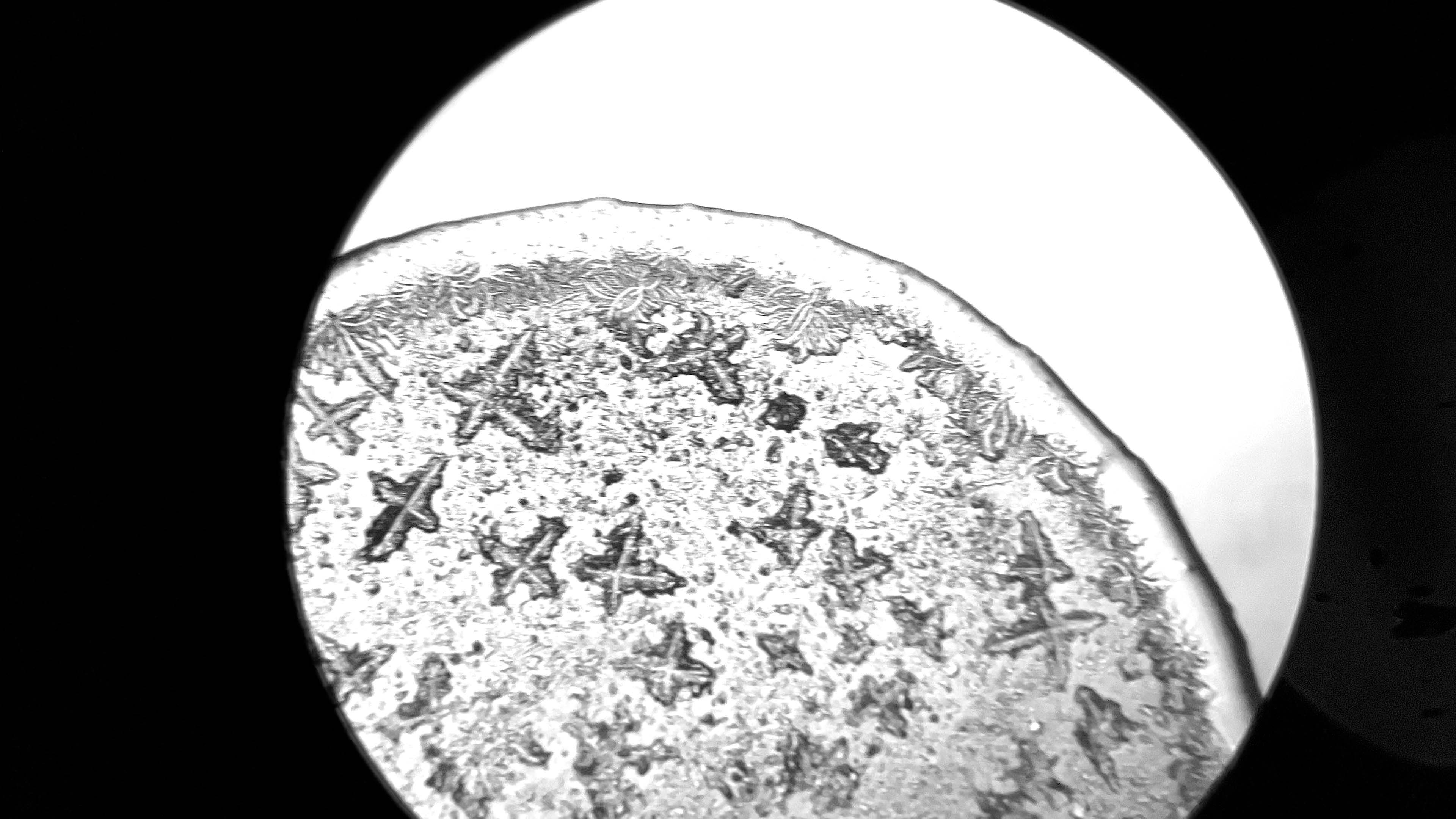
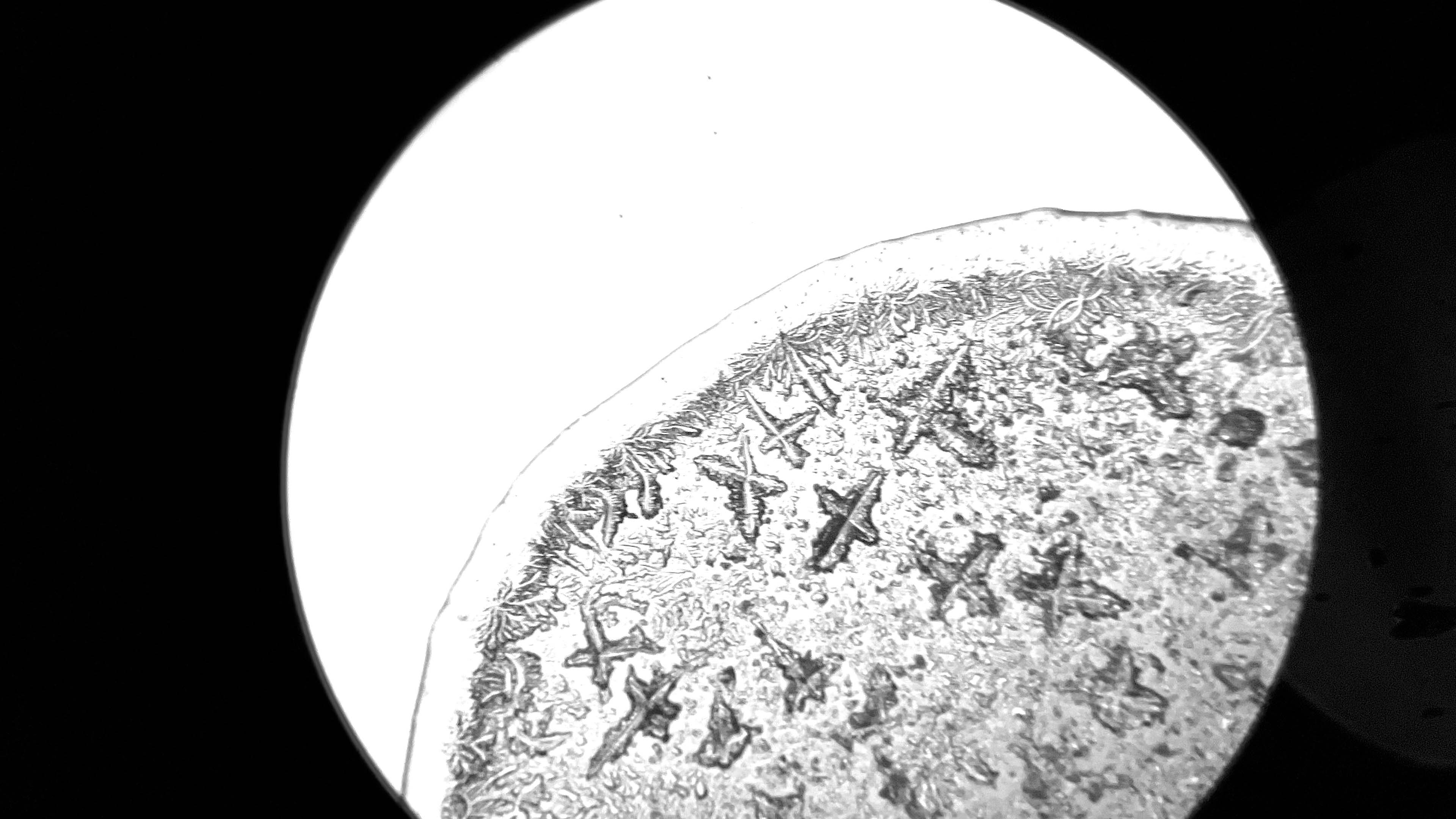
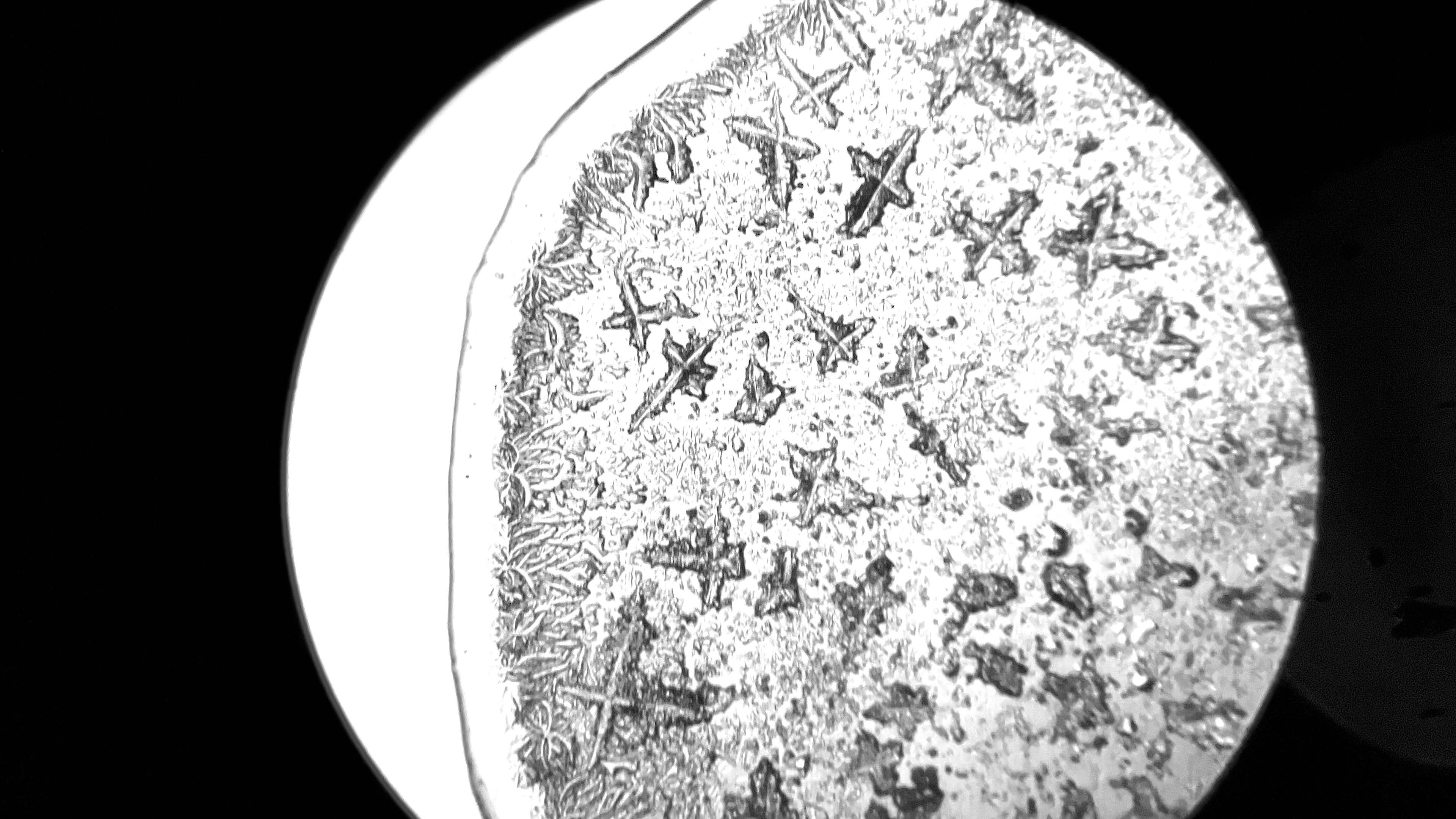
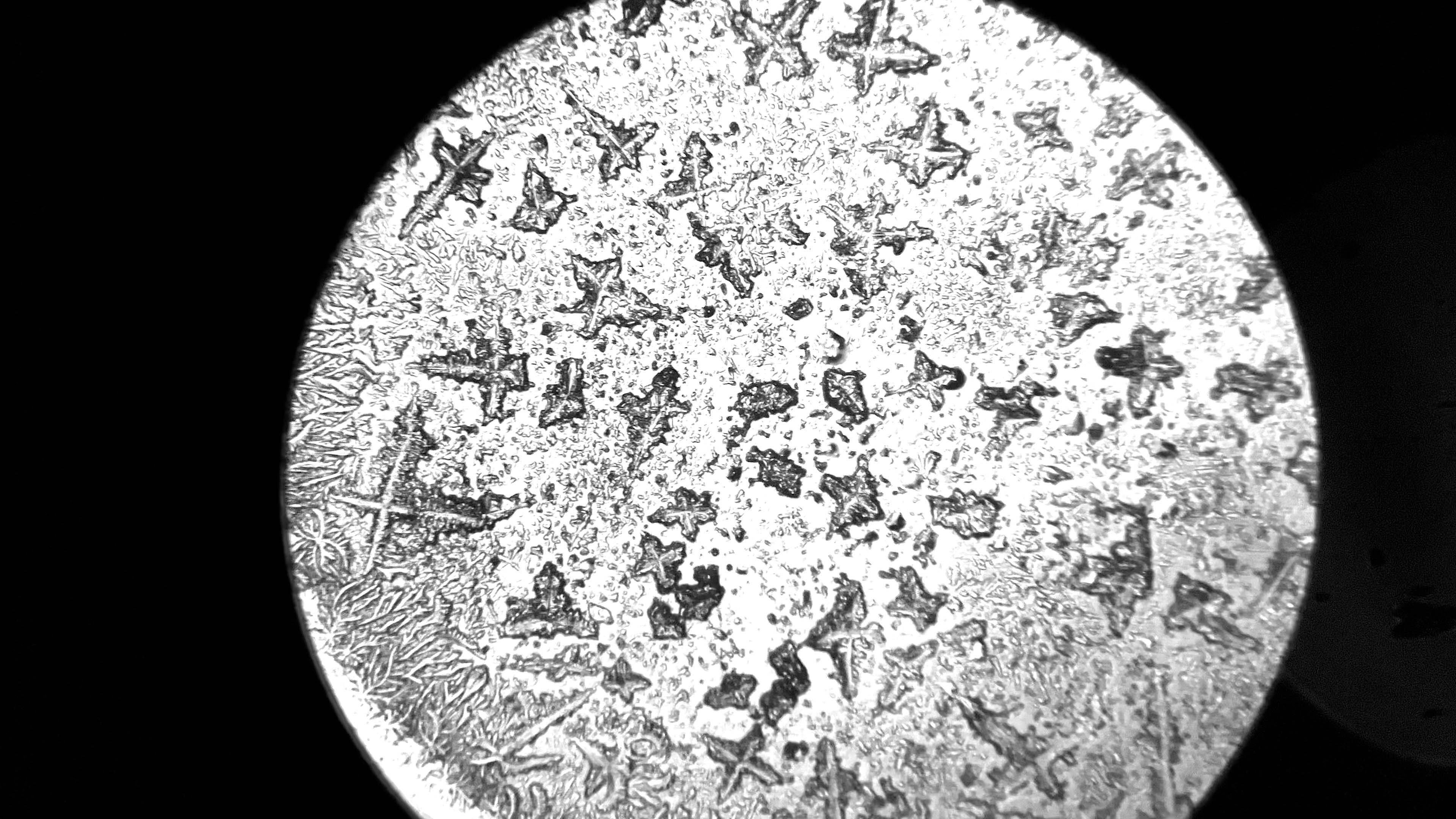
During a workshop held at the fab lab in collaboration with the microbiology laboratory, participants have produced photos and videos of tears observed under the microscope. The aim is to use this footage to create an interactive environment that could make explorable, in a more aesthetic and less scientific key, two of the videos made. So you can analyze frame by frame how the crystallization of tears happens in contact with air, or generally how tears under microscope vision appear.
Tears

Disassembled object











WEB PLATFORM
A short demo of how gestures works to control "play, pause, rewind and shuffle "
Play
Instructions: no poses activates: Play.
Pause
Instructions: right hand raised activates: Pause.
How Does Pose Estimation Works
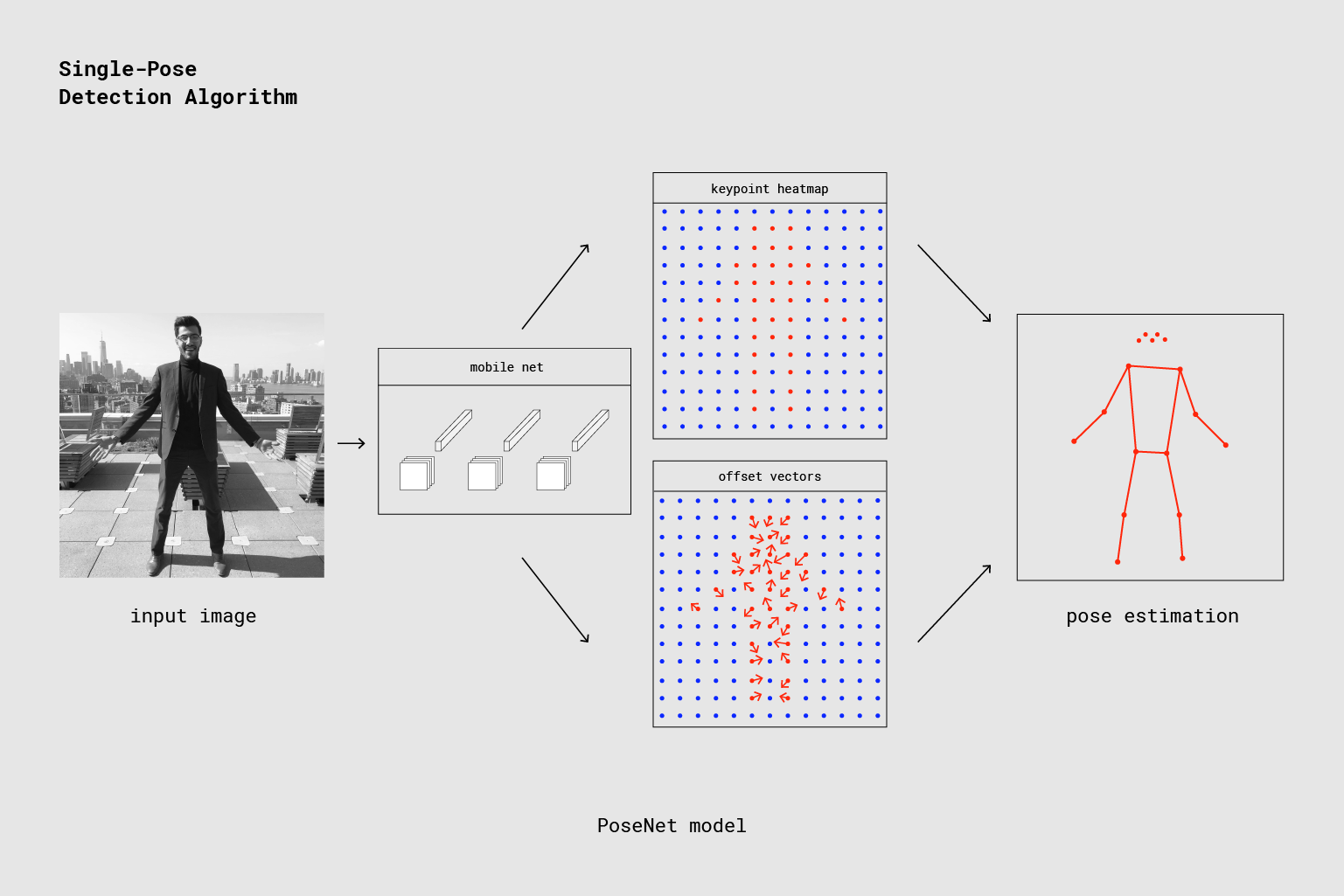
www.baeldung.com
"In photos or videos, human pose estimation recognizes and categorizes the positions of human body
components
and joints. To represent and infer human body positions in 2D and 3D space, a model-based technique is
typically used. One particular class of flexible objects includes people. Keypoints will be in different
positions concerning others when we bend our arms or legs.
The goal of human pose estimation is to foretell the positions of joints and body parts in still photos and
moving pictures. Knowing a person’s body pose is essential for identifying actions since certain human
behaviors frequently influence pose motions.
Human pose estimation involves describing the joints of the human body, such as the wrist, shoulder, knees,
eyes, ears, ankles, and arms, which are crucial in pictures and videos that can depict a person’s position."
Rewind
Instructions: left hand raised activates: Rewind.
Shuffle
Instructions: no person detected activates: Shuffle.
Step By Step Process
Figma Protype

Pre & Post Video Color Grading
Both videos have been color-graded to make them more homogeneous and make the animation perceptually smoother.
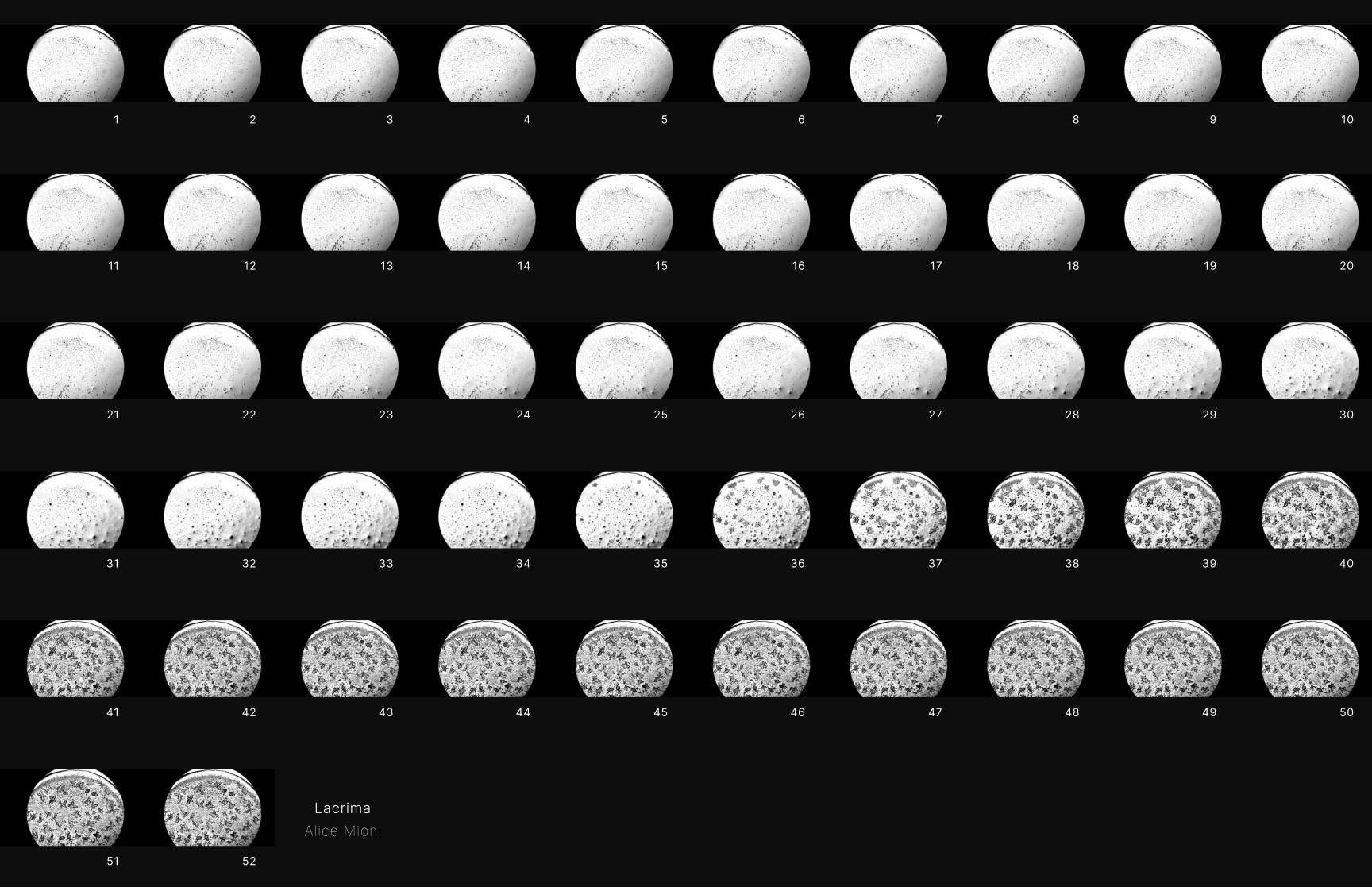
Videos Frame By Frame Export in PNGs
For each video, one frame was extracted every 5 seconds in order to have a dataset of images.
Photoshop "Crop And Center IMGs" Batch
I had to create a micro script on photoshop to center all the frames extracted from the 2 videos used,
and to recreate the two arcs of the circumference (upper and lower) missing from each image..
Training Machine Learning Models
Teachable Machine 1st Train With Image Classification - Gone Wrong
Teachable Machine 2nd Train With Image Classification - Gone Wrong
Teachable Machine 3rd Train With Image Classification - Gone Wrong
Teachable Machine - Definitive Train With Pose
After 3 trials with the "image classification method", I came to the conclusion that:
to perform this type of tasks the best way is via the posenet framework, since it also allows the project to
be usable by others and not to be affected by different backgrounds, clothes, glasses etc.